Hongyang Li
Ph.D Student @ South China University of Technology
Research Intern @ International Digital Economy Academy (IDEA)
Guangdong-HongKong-Macau Greater Bay Area
Shenzhen, China
Email: ftwangyeunglei AT mail dot scut dot edu dot cn

Ph.D Student @ South China University of Technology
Research Intern @ International Digital Economy Academy (IDEA)
Guangdong-HongKong-Macau Greater Bay Area
Shenzhen, China
Email: ftwangyeunglei AT mail dot scut dot edu dot cn
Hi! This is Hongyang Li, 李弘洋 in Chinese. I’m a second-year year Ph.D. student (2022-now) at the Department of Future Technology, South China University of Technology, supervised by Prof.Lei Zhang. I interned at International Digital Economy Academy. Previously, I obtained my bachelor’s degree from School of Electrical Engineering in South China University of Technology in 2021.
🔖 My research interests lie in General Perception, World Model and Embodied AI.
💬 Feel free to contact me for any discussion and coorperation.
[2026/1] OVSeg3R and TAPTRv3 are accepted by ICLR2026!
[2025/10] OVSeg3R is released! Check out our OVSeg3R for more details.
[2025/9] SegDINO3D is accepted by AAAI2025! Check out our SegDINO3D for more details.
[2025/5] TAPTR3D is accepted by SPL2025! Check out our TAPTR3D for more details.
[2025/1] Supported by China Association for Science and Technology Youth Ph.D Talent Support Project, Supported by CAAI (首届中国科协青年人才托举工程博士生专项计划, 托举学会:中国人工智能学会)
[2024/12] TAPTRv3 is released! Check out our TAPTRv3 for more details.
[2024/9] TAPTRv2 is accepted by NeurIPS2024.
[2024/7] TAPTRv2 is released! Check out our TAPTRv2 for more details.
[2024/7] Two papers are accepted by ECCV2024! Check out our TAPTR and LLaVA-Grounding for more details.
[2024/3] We release TAPTR. Check out project page for more details and online demos.
[2023/12] We release LLaVA-Grounding. Demo and inference code are available.
[2023/7] Two papers are accepted by ICCV2023. Check out our DFA3D and StableDINO.
[2023/2] We release DA-BEV that establishes a new SOTA performance on nuScenes 3D detection leaderboard–camera track. Check out our DA-BEV.
[2022/7] A paper is accepted by ECCV2022! Check out our DCL-Net.
[2021/9] A paper is accepted by NeurIPS2021! Check out our Sparse Steerable Convolution.
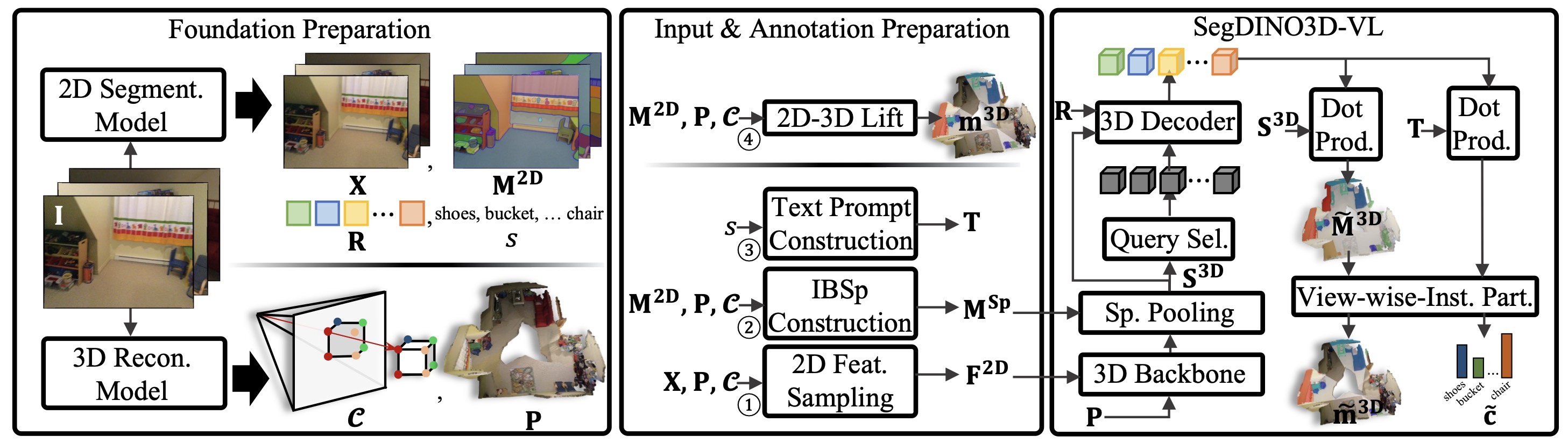
@article{li2025ovseg3r,
title={OVSeg3R: Learn Open-vocabulary Instance Segmentation from 2D via 3D Reconstruction},
author={Li, Hongyang and Qu, Jinyuan and Zhang, Lei},
journal={arXiv preprint arXiv:2509.23541},
year={2025}
}
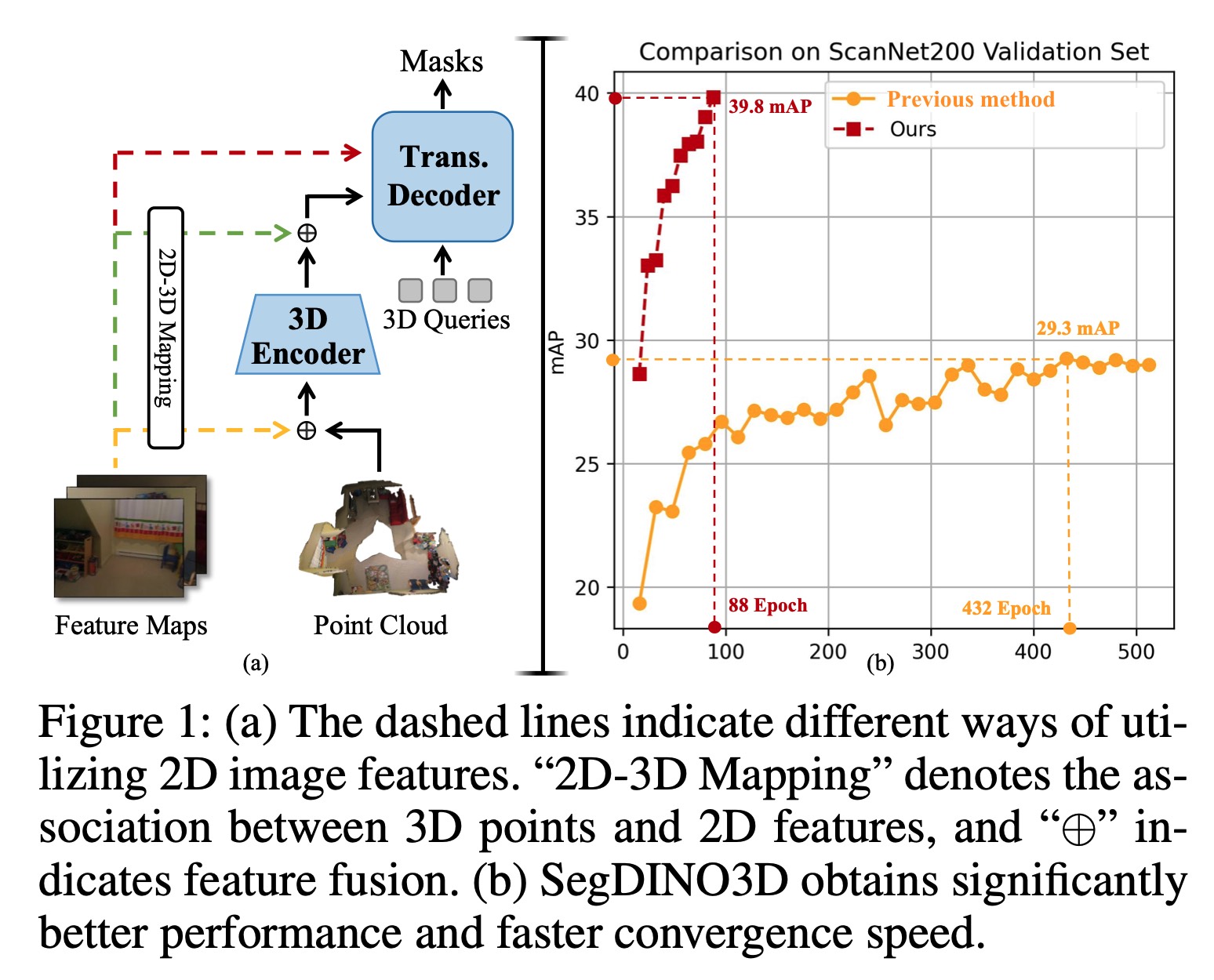
@inproceedings{qu2025segdino3d,
title={SegDINO3D: 3D Instance Segmentation Empowered by Both Image-Level and Object-Level 2D Features},
author={Qu, Jinyuan and Li, Hongyang and Chen, Xingyu and Liu, Shilong and Shi, Yukai and Ren, Tianhe and Jing, Ruitao and Zhang, Lei},
booktitle={Proceedings of the AAAI conference on artificial intelligence},
year={2025}
}
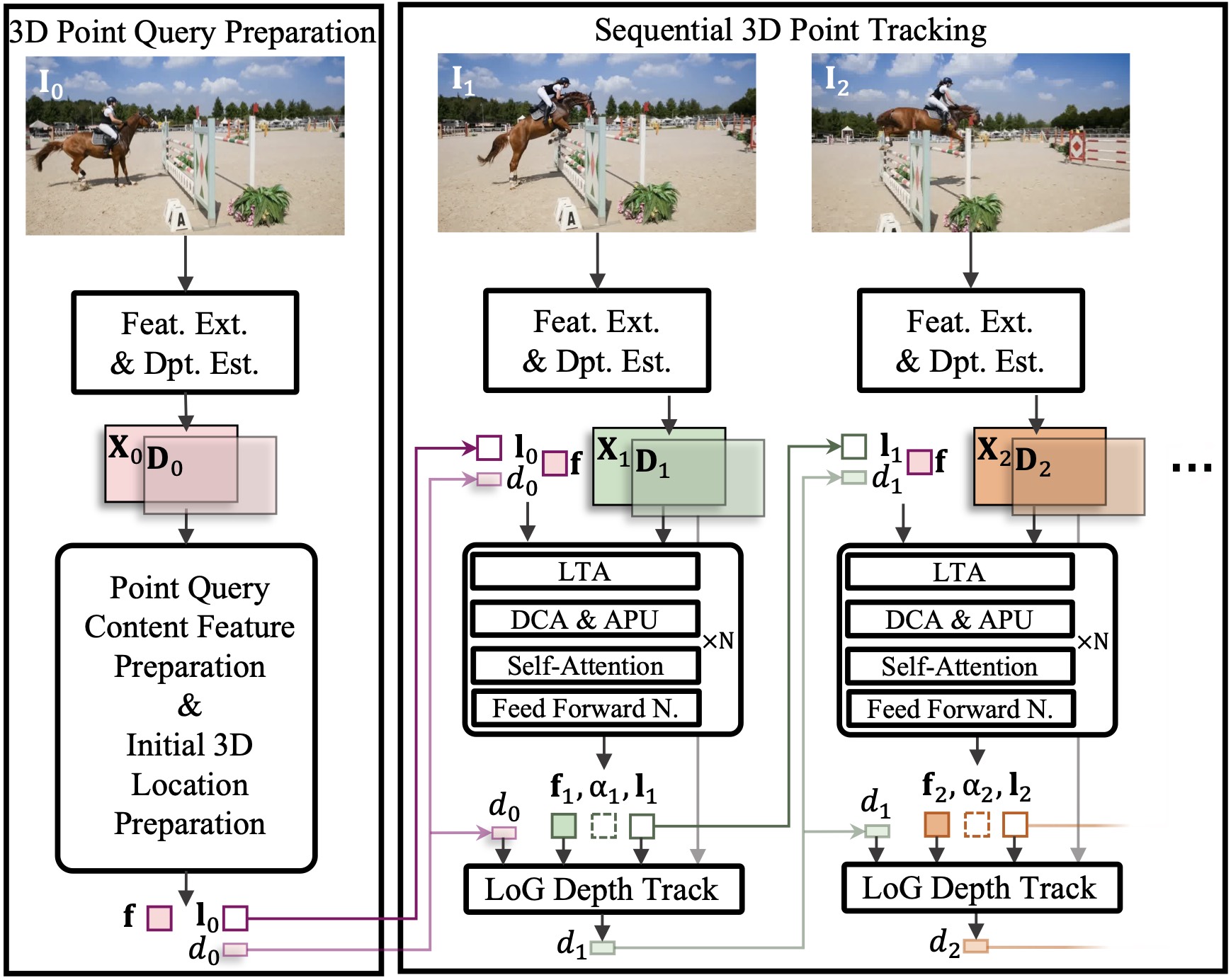
@article{li2025taptr3d,
title={{TAPTR3D: Decoupled 3D Point Tracking Boosts 2D and Further Enhances 3D Tracking Accuracy}},
author={Li, Hongyang and Qu, Jinyuan and Zeng, Zhaoyang and Zhang, Lei},
journal={IEEE Signal Processing Letters},
year={2025},
publisher={IEEE}
}
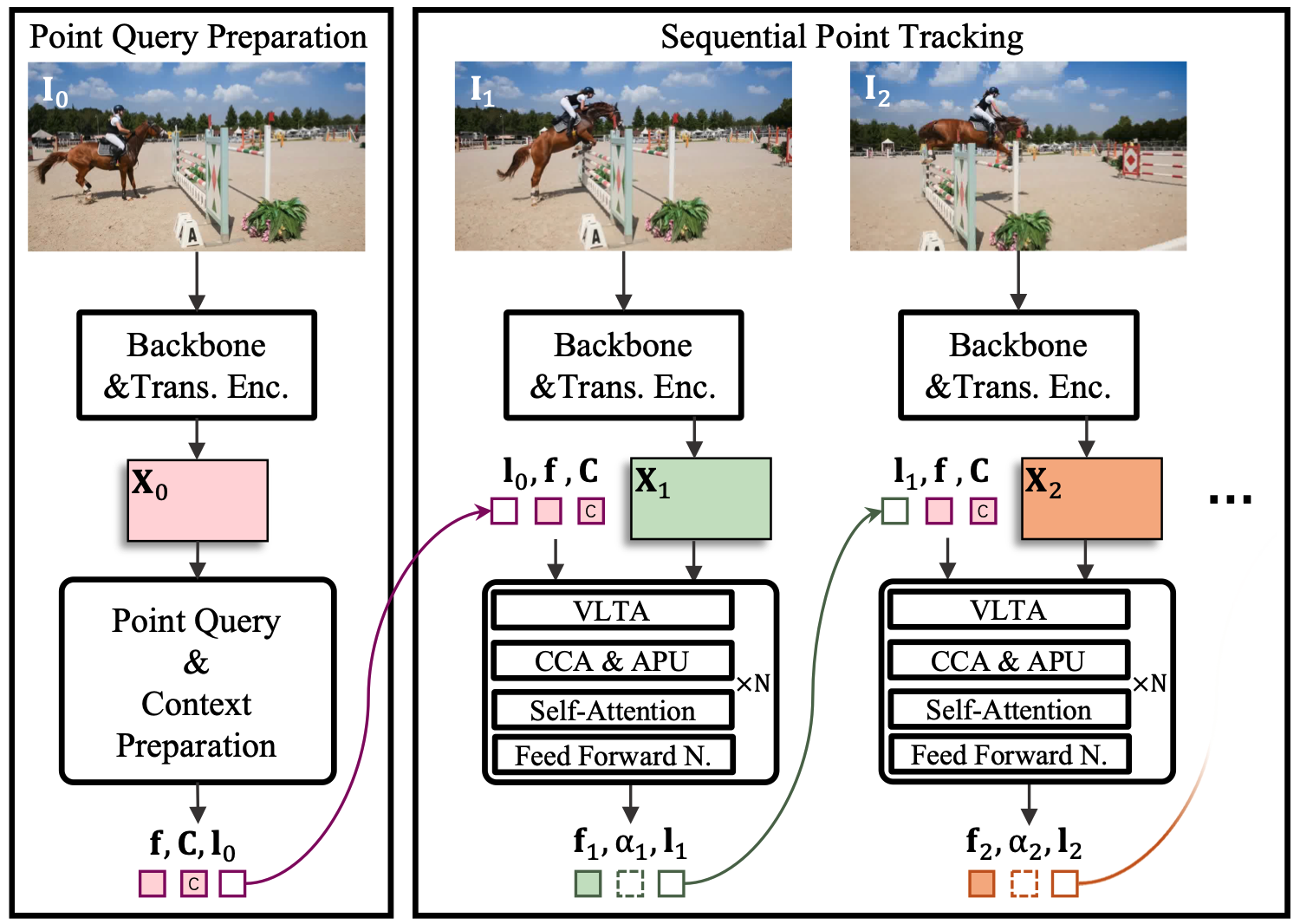
@article{Qu2024taptrv3,
title={{TAPTRv3: Spatial and Temporal Context Foster Robust Tracking of Any Point in Long Video}},
author={Qu, Jinyuan and Li, Hongyang and Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Zhang, Lei},
journal={arXiv preprint},
year={2024}
}
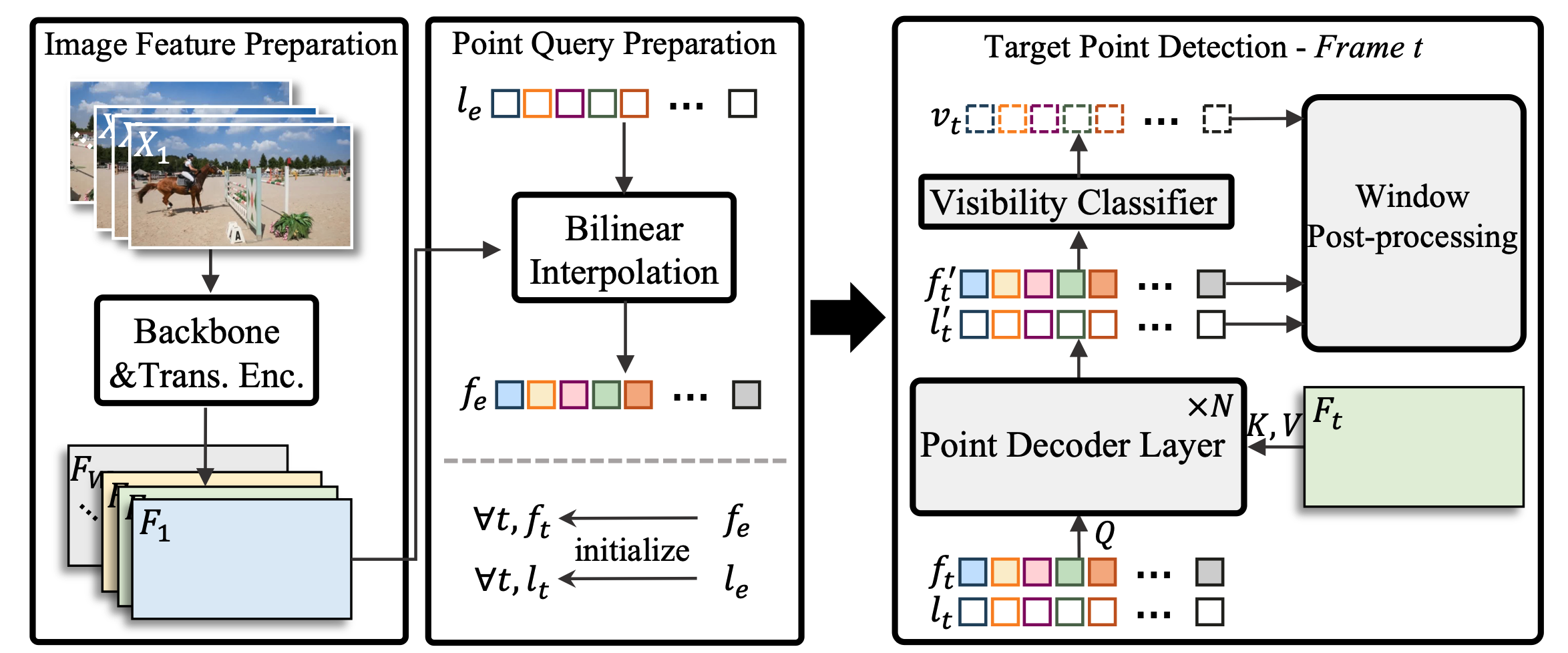
@article{li2024taptrv2,
title={TAPTRv2: Attention-based Position Update Improves Tracking Any Point},
author={Li, Hongyang and Zhang, Hao and Liu, Shilong and Zeng, Zhaoyang and Li, Feng and Ren, Tianhe and Bohan Li and Zhang, Lei},
journal={arXiv preprint arXiv:2407.16291},
year={2024}
}
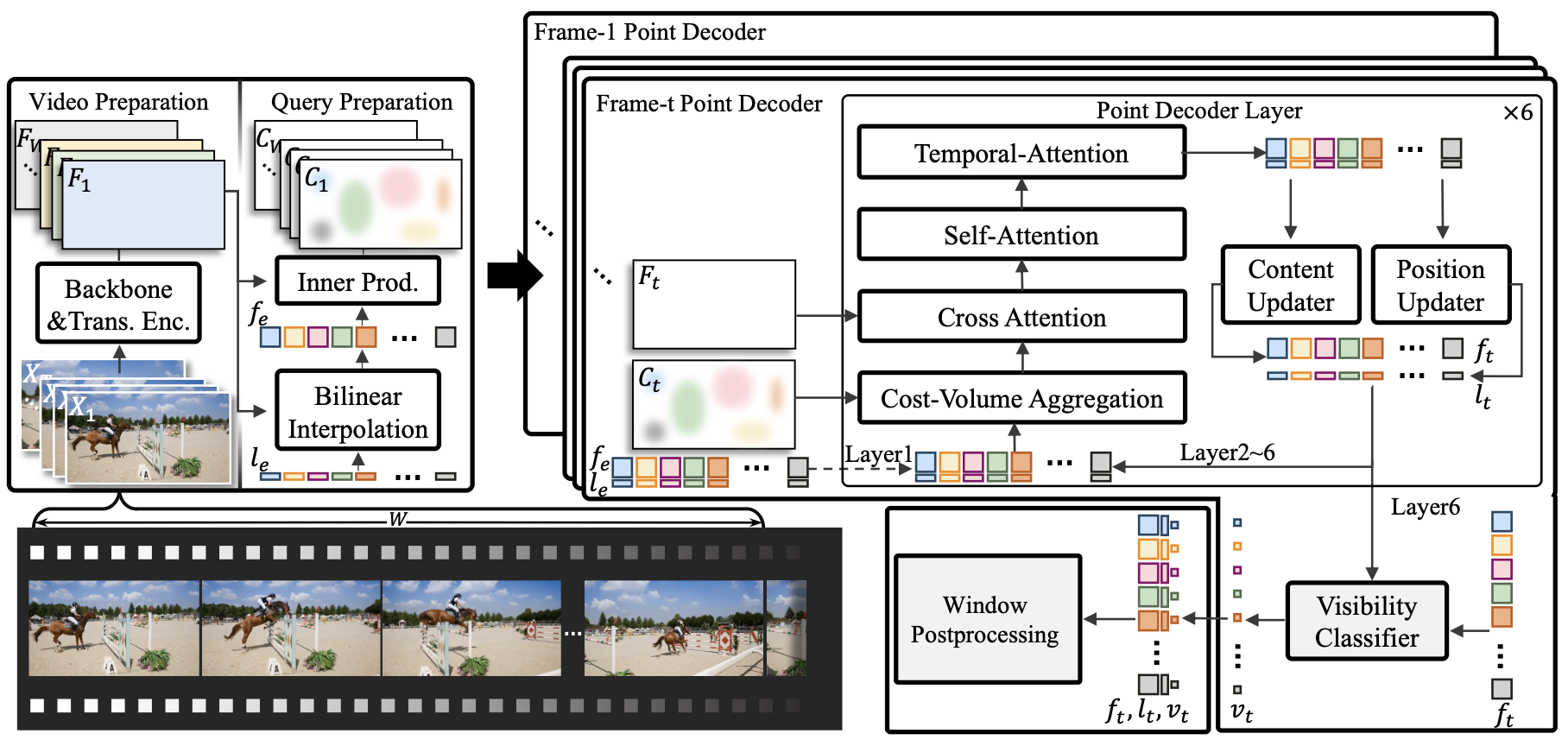
@article{li2024taptr,
title={TAPTR: Tracking Any Point with Transformers as Detection},
author={Li, Hongyang and Zhang, Hao and Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Lei},
journal={arXiv preprint arXiv:2403.13042},
year={2024}
}
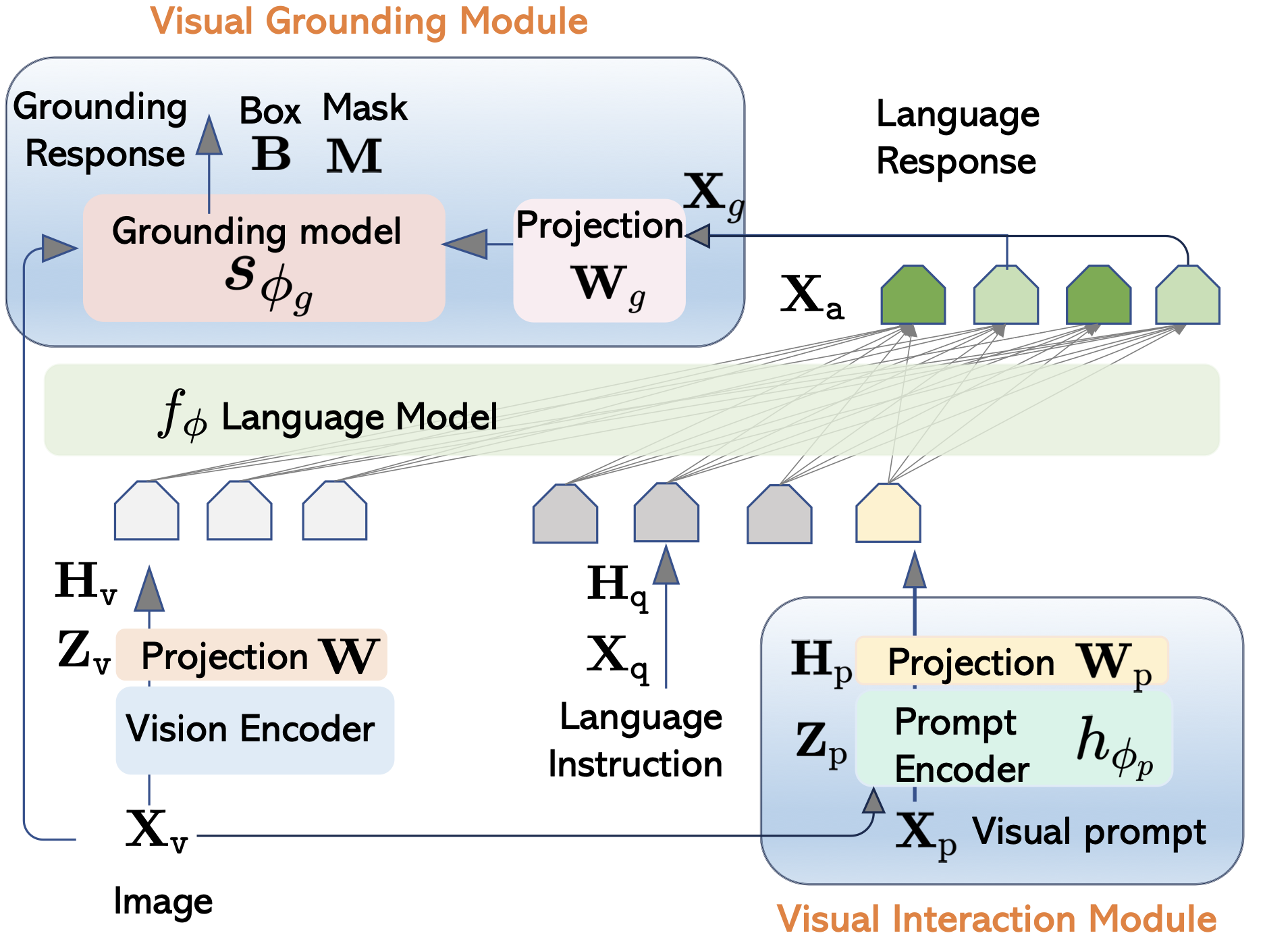
@article{zhang2023llava,
title={Llava-grounding: Grounded visual chat with large multimodal models},
author={Zhang, Hao and Li, Hongyang and Li, Feng and Ren, Tianhe and Zou, Xueyan and Liu, Shilong and Huang, Shijia and Gao, Jianfeng and Zhang, Lei and Li, Chunyuan and others},
journal={arXiv preprint arXiv:2312.02949},
year={2023}
}
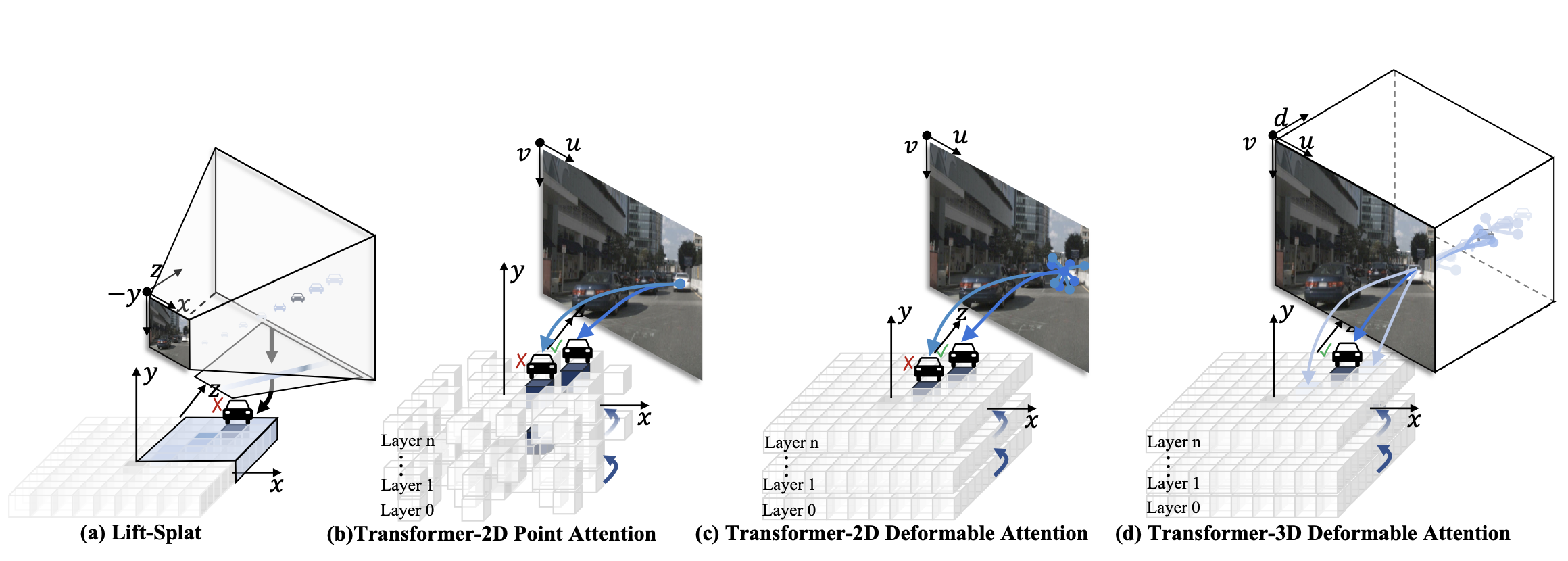
@inproceedings{li2023dfa3d,
title={DFA3D: 3D Deformable Attention For 2D-to-3D Feature Lifting},
author={Li, Hongyang and Zhang, Hao and Zeng, Zhaoyang and Liu, Shilong and Li, Feng and Ren, Tianhe and Zhang, Lei},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={6684--6693},
year={2023}
}
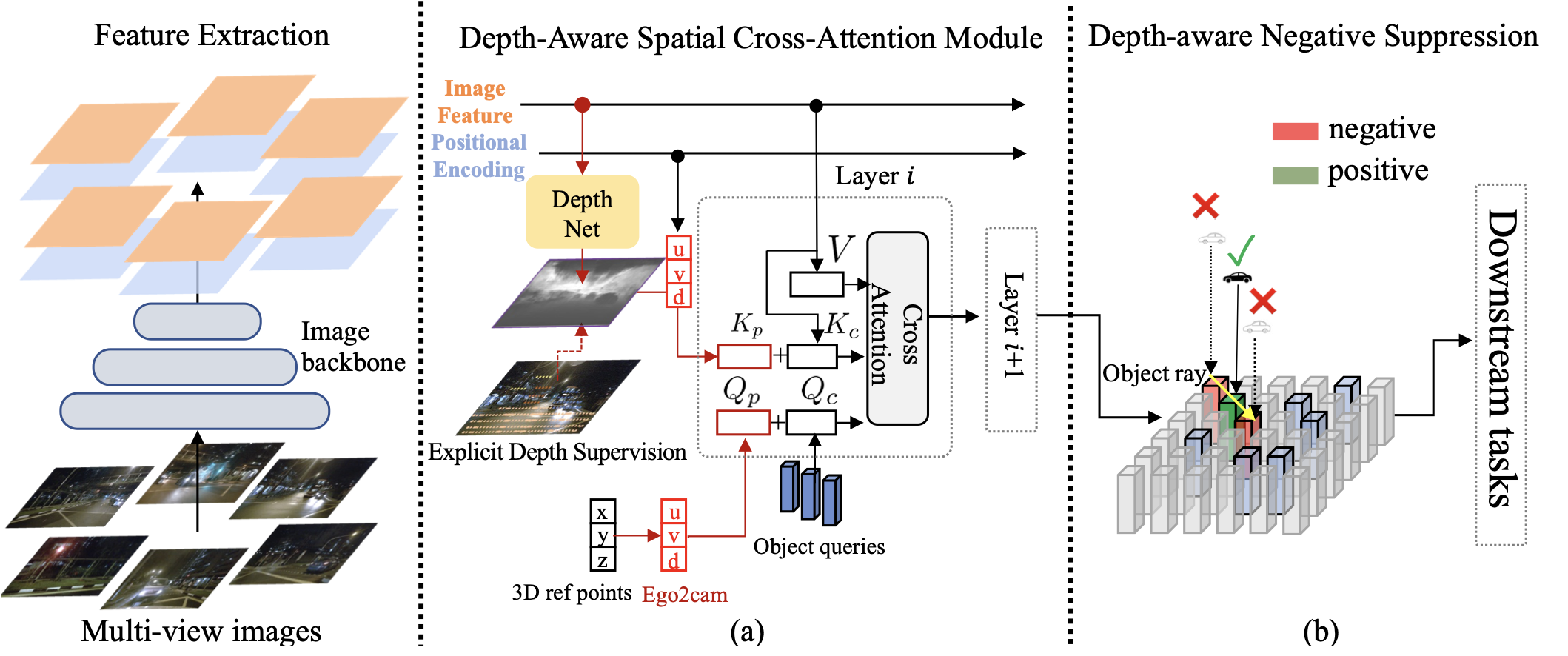
@article{zhang2023bev,
title={Da-bev: Depth aware bev transformer for 3d object detection},
author={Zhang, Hao and Li, Hongyang and Liao, Xingyu and Li, Feng and Liu, Shilong and Ni, Lionel M and Zhang, Lei},
journal={arXiv e-prints},
pages={arXiv--2302},
year={2023}
}
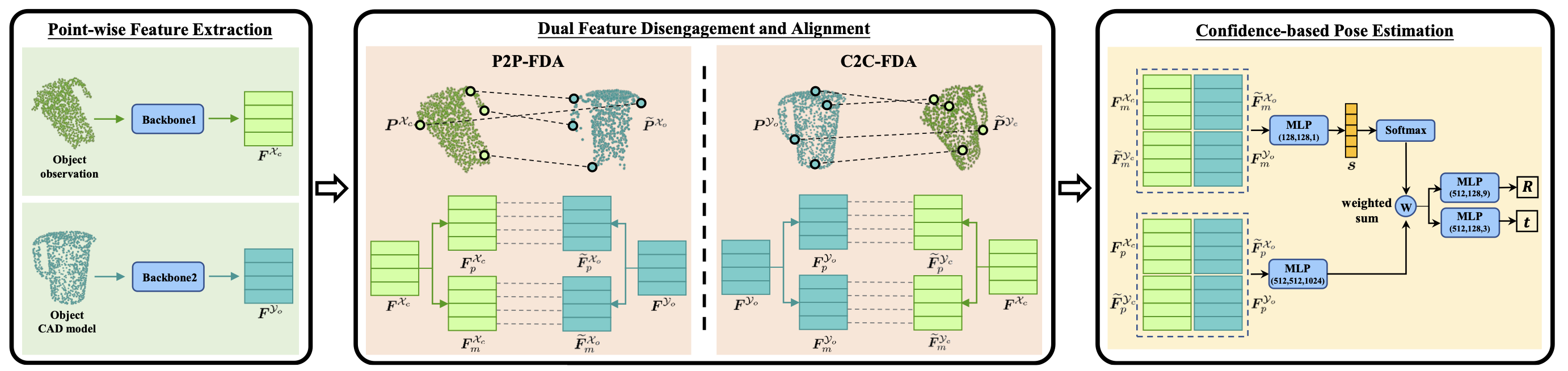
@inproceedings{li2022dcl,
title={DCL-Net: Deep Correspondence Learning Network for 6D Pose Estimation},
author={Li, Hongyang and Lin, Jiehong and Jia, Kui},
booktitle={European Conference on Computer Vision},
pages={369--385},
year={2022},
organization={Springer}
}
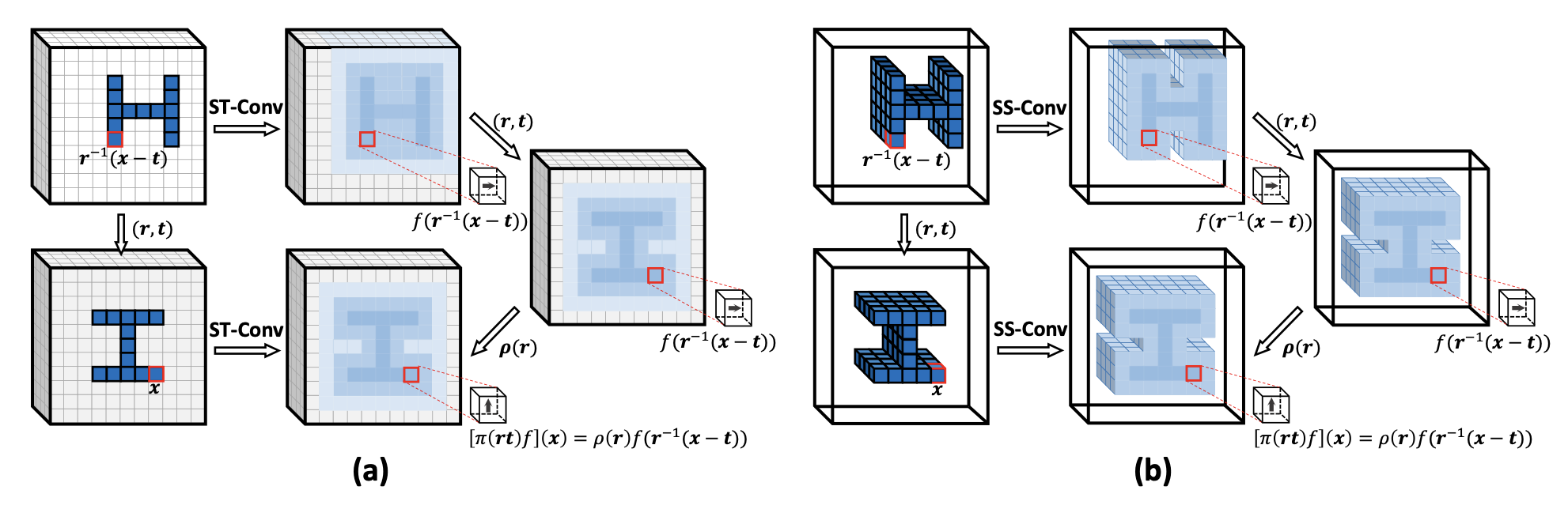
@article{lin2021sparse,
title={Sparse steerable convolutions: An efficient learning of se (3)-equivariant features for estimation and tracking of object poses in 3d space},
author={Lin, Jiehong and Li, Hongyang and Chen, Ke and Lu, Jiangbo and Jia, Kui},
journal={Advances in Neural Information Processing Systems},
volume={34},
pages={16779--16790},
year={2021}
}
Principal's Scholarship & National Scholarships in 2022, 2023, 2024.
The First Prize Scholarship in 2018, 2019, 2020.