Hongyang Li
-
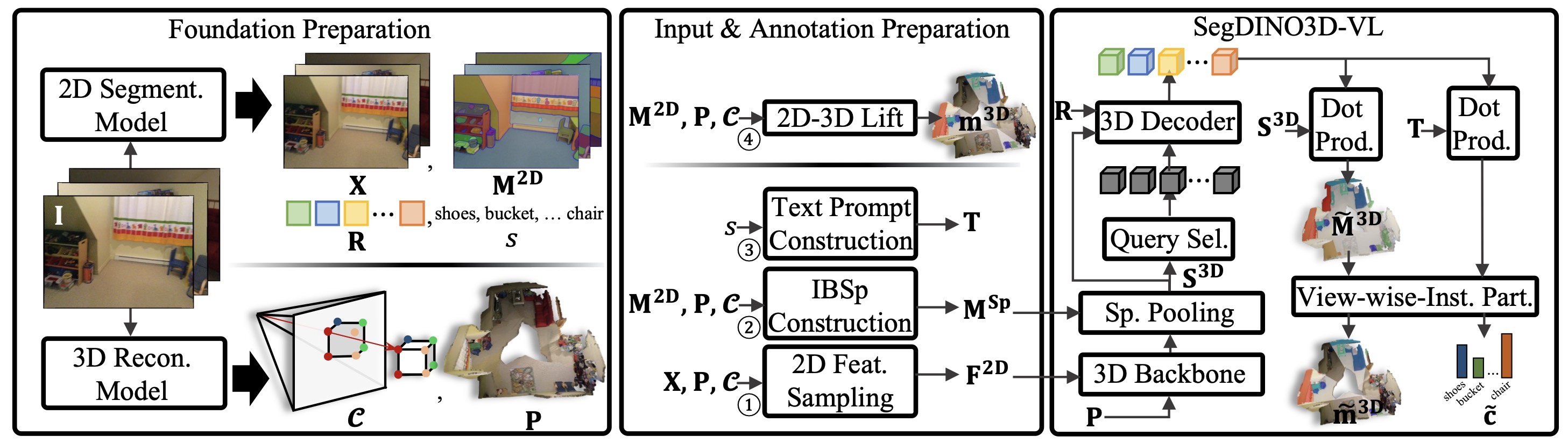 OVSeg3R: Learn Open-vocabulary Instance Segmentation from 2D via 3D ReconstructionICLR, 2026
OVSeg3R: Learn Open-vocabulary Instance Segmentation from 2D via 3D ReconstructionICLR, 2026@article{li2025ovseg3r, title={OVSeg3R: Learn Open-vocabulary Instance Segmentation from 2D via 3D Reconstruction}, author={Li, Hongyang and Qu, Jinyuan and Zhang, Lei}, journal={arXiv preprint arXiv:2509.23541}, year={2025} } -
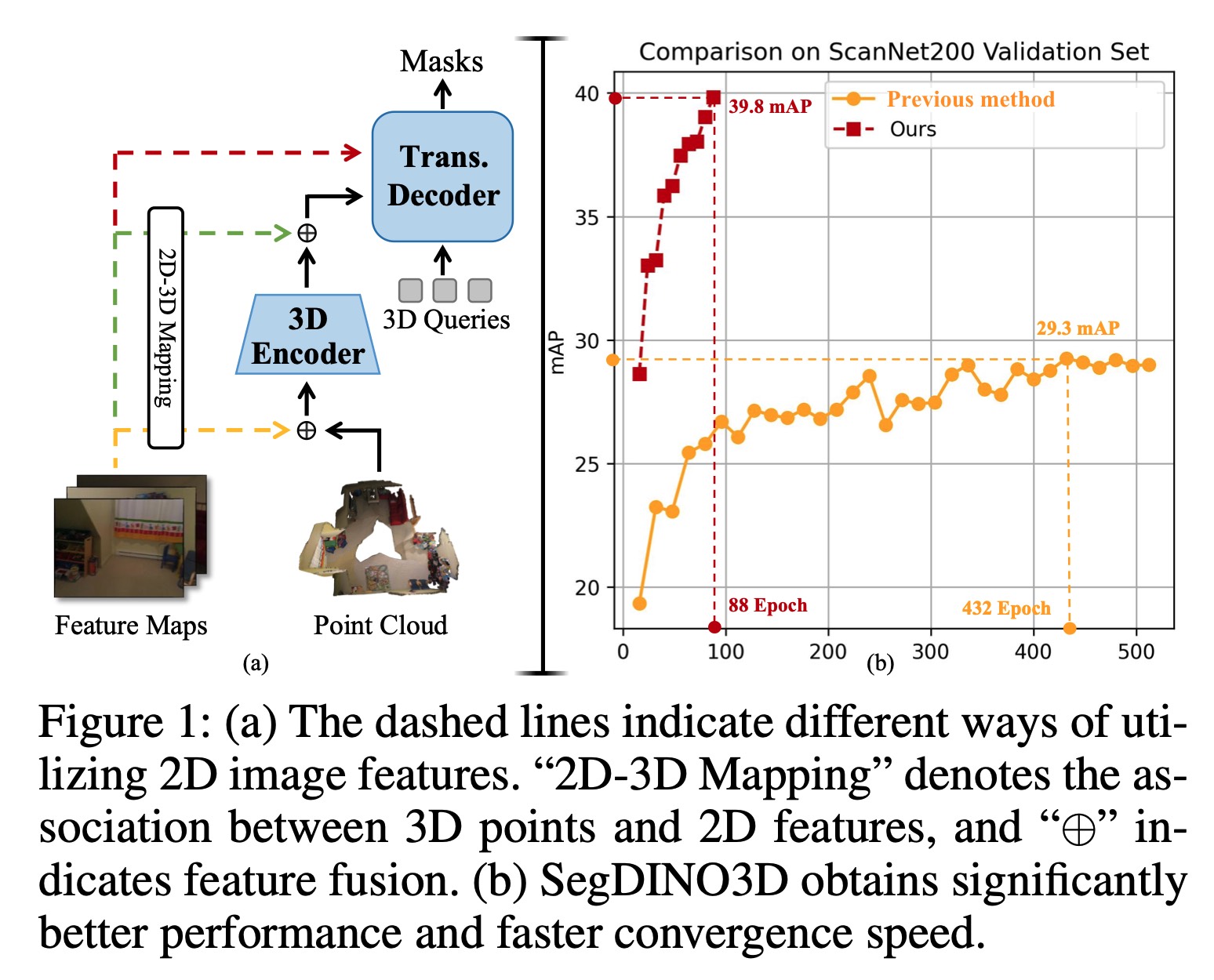 SegDINO3D: 3D Instance Segmentation Empowered by Both Image-Level and Object-Level 2D FeaturesAAAI, 2025
SegDINO3D: 3D Instance Segmentation Empowered by Both Image-Level and Object-Level 2D FeaturesAAAI, 2025@inproceedings{qu2025segdino3d, title={SegDINO3D: 3D Instance Segmentation Empowered by Both Image-Level and Object-Level 2D Features}, author={Qu, Jinyuan and Li, Hongyang and Chen, Xingyu and Liu, Shilong and Shi, Yukai and Ren, Tianhe and Jing, Ruitao and Zhang, Lei}, booktitle={Proceedings of the AAAI conference on artificial intelligence}, year={2025} } -
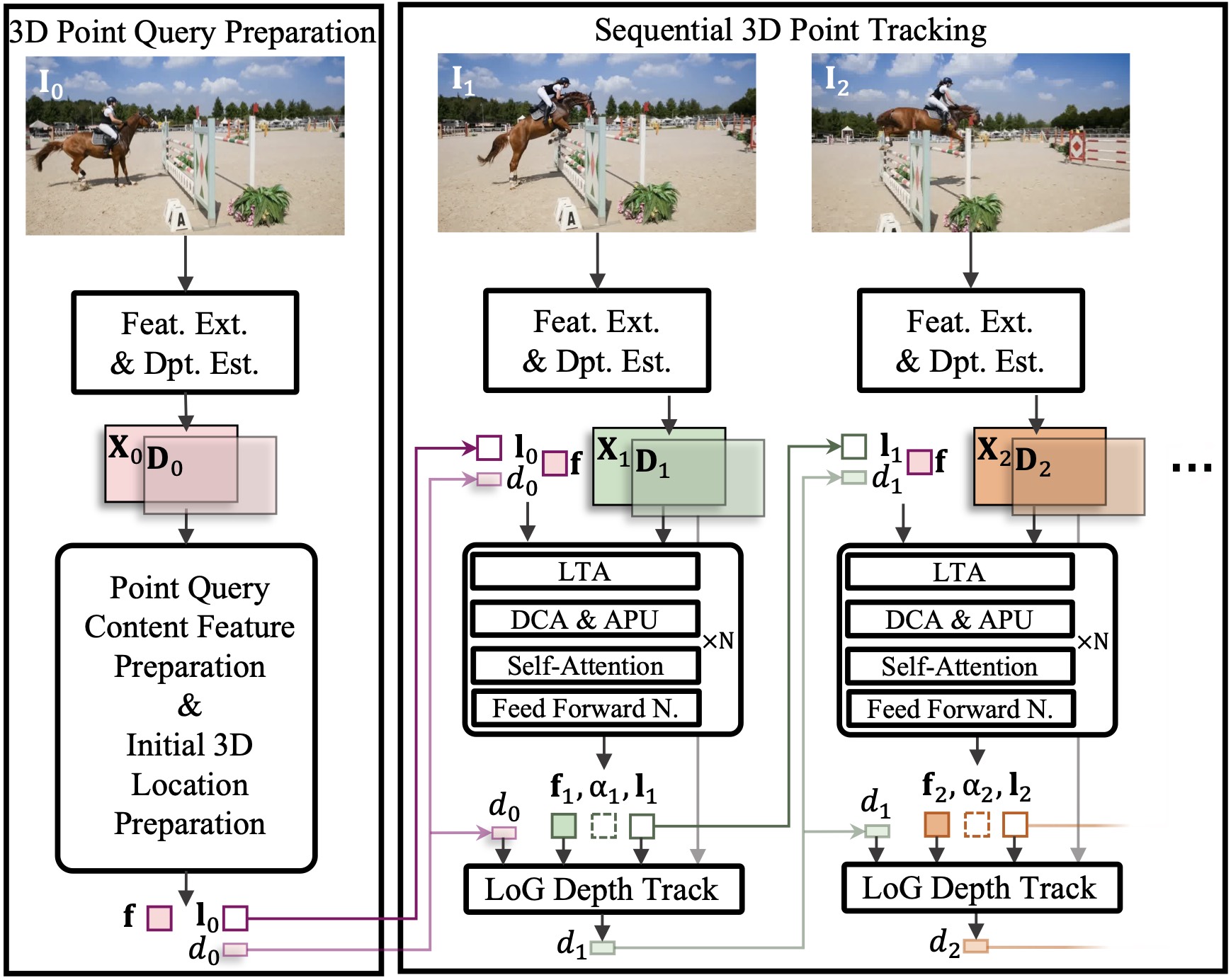 TAPTR3D: Decoupled 3D Point Tracking Boosts 2D and Further Enhances 3D Tracking AccuracyIEEE SPL, 2025
TAPTR3D: Decoupled 3D Point Tracking Boosts 2D and Further Enhances 3D Tracking AccuracyIEEE SPL, 2025@article{li2025taptr3d, title={{TAPTR3D: Decoupled 3D Point Tracking Boosts 2D and Further Enhances 3D Tracking Accuracy}}, author={Li, Hongyang and Qu, Jinyuan and Zeng, Zhaoyang and Zhang, Lei}, journal={IEEE Signal Processing Letters}, year={2025}, publisher={IEEE} } -
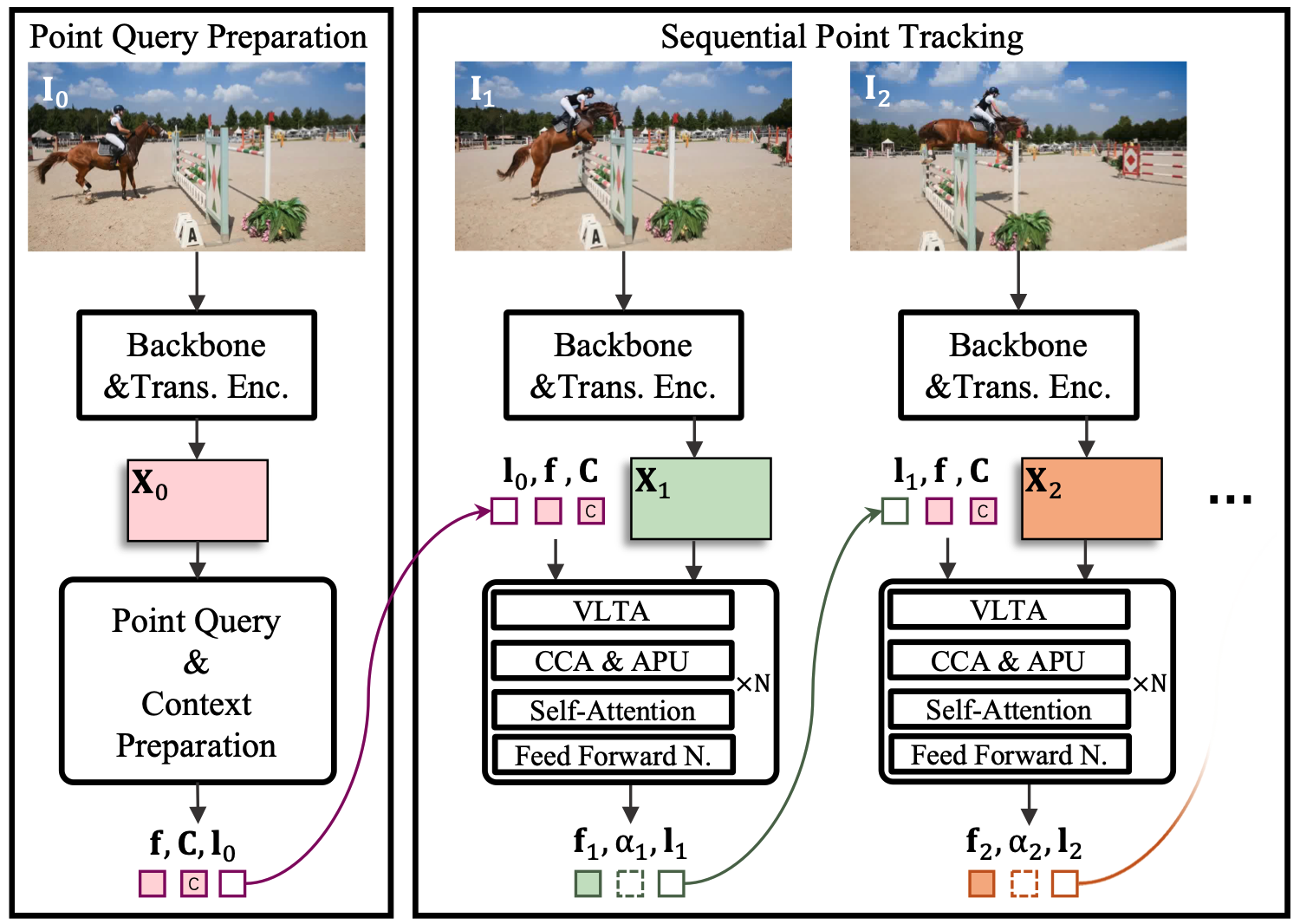 TAPTRv3: Spatial and Temporal Context Foster Robust Tracking of Any Point in Long VideoICLR, 2026
TAPTRv3: Spatial and Temporal Context Foster Robust Tracking of Any Point in Long VideoICLR, 2026@article{Qu2024taptrv3, title={{TAPTRv3: Spatial and Temporal Context Foster Robust Tracking of Any Point in Long Video}}, author={Qu, Jinyuan and Li, Hongyang and Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Zhang, Lei}, journal={arXiv preprint}, year={2024} } -
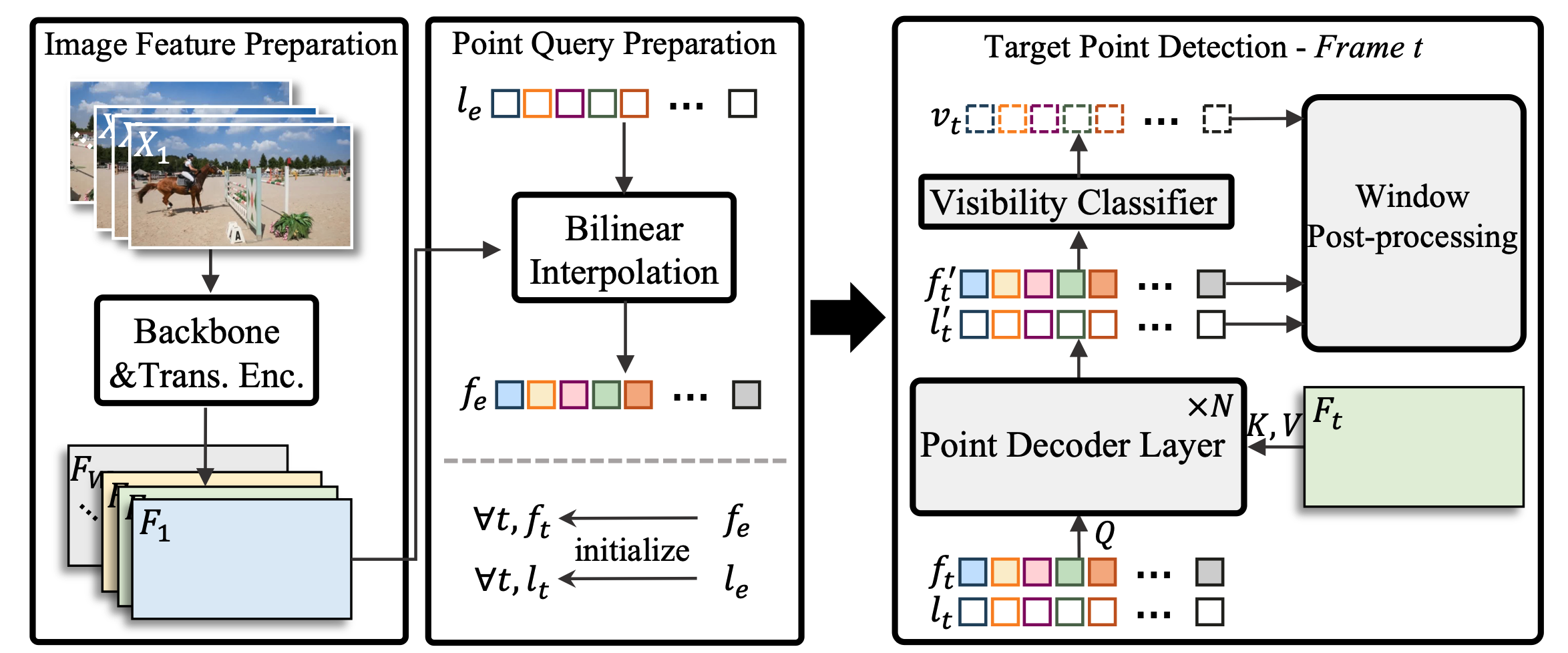 TAPTRv2: Attention-based Position Update Improves Tracking Any PointNeurIPS, 2024
TAPTRv2: Attention-based Position Update Improves Tracking Any PointNeurIPS, 2024@article{li2024taptrv2, title={TAPTRv2: Attention-based Position Update Improves Tracking Any Point}, author={Li, Hongyang and Zhang, Hao and Liu, Shilong and Zeng, Zhaoyang and Li, Feng and Ren, Tianhe and Bohan Li and Zhang, Lei}, journal={arXiv preprint arXiv:2407.16291}, year={2024} } -
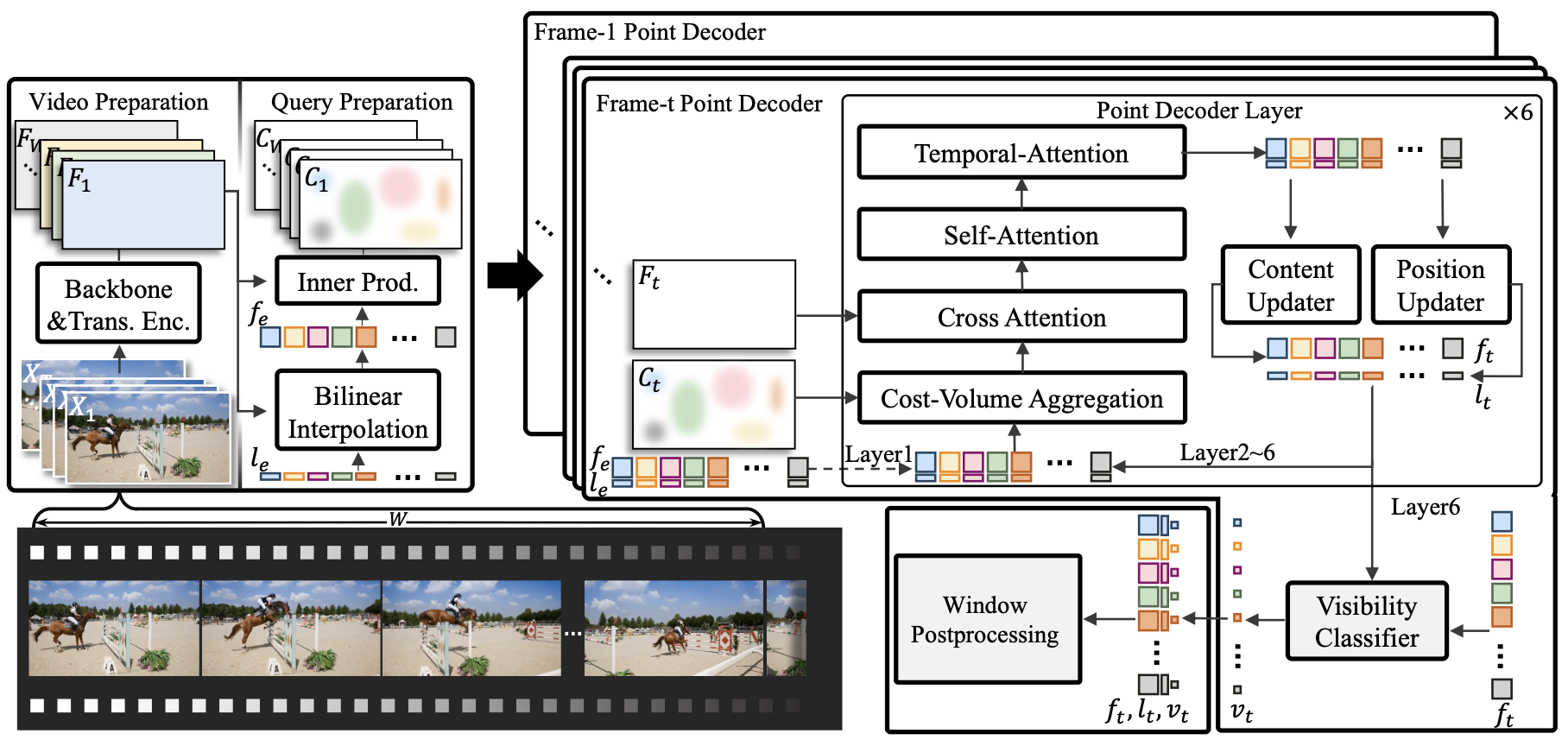 TAPTR: Tracking Any Point with Transformers as DetectionECCV, 2024
TAPTR: Tracking Any Point with Transformers as DetectionECCV, 2024@article{li2024taptr, title={TAPTR: Tracking Any Point with Transformers as Detection}, author={Li, Hongyang and Zhang, Hao and Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Lei}, journal={arXiv preprint arXiv:2403.13042}, year={2024} } -
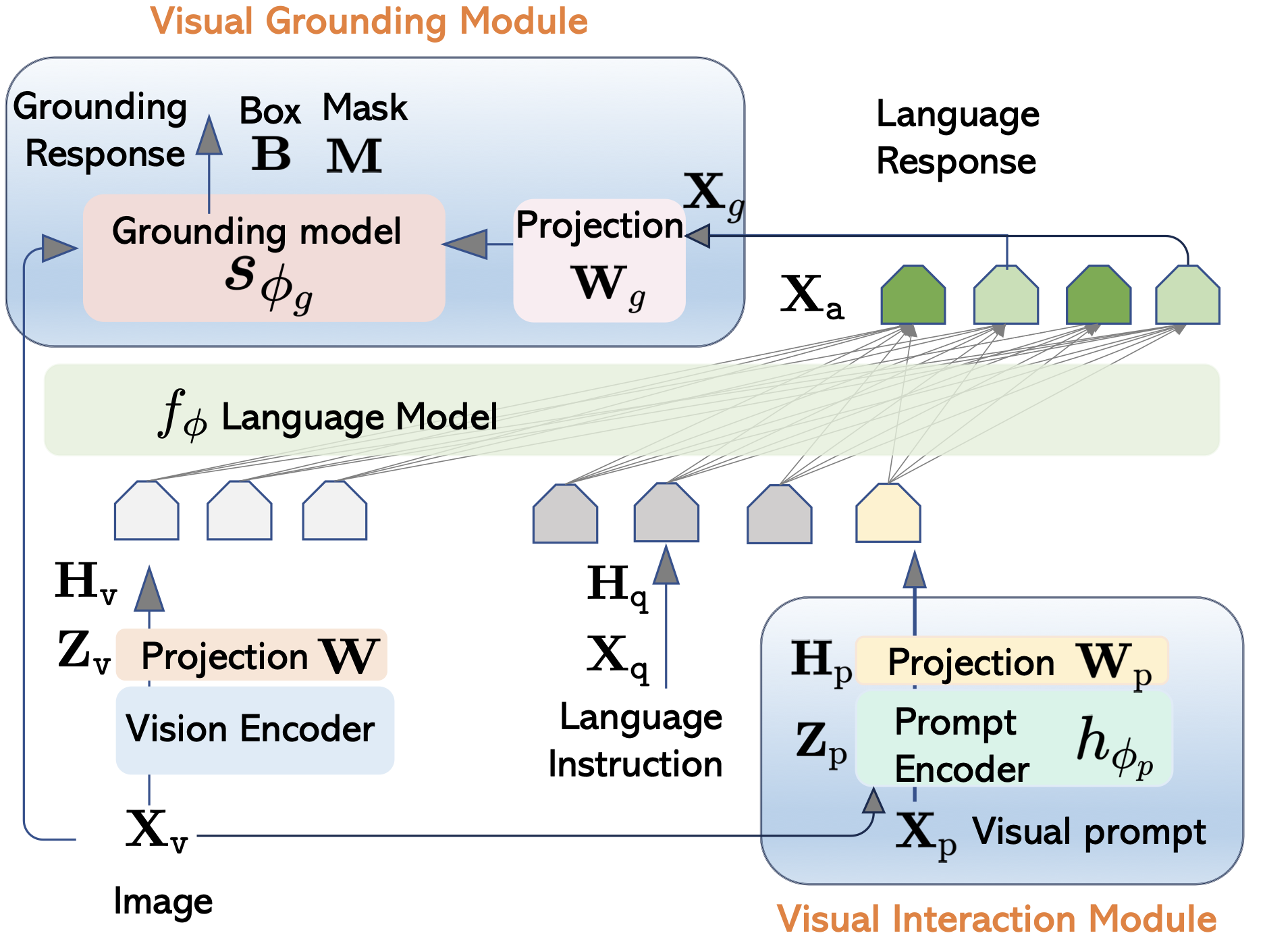 LLaVA-Grounding: Grounded Visual Chat with Large Multimodal ModelsECCV, 2024
LLaVA-Grounding: Grounded Visual Chat with Large Multimodal ModelsECCV, 2024@article{zhang2023llava, title={Llava-grounding: Grounded visual chat with large multimodal models}, author={Zhang, Hao and Li, Hongyang and Li, Feng and Ren, Tianhe and Zou, Xueyan and Liu, Shilong and Huang, Shijia and Gao, Jianfeng and Zhang, Lei and Li, Chunyuan and others}, journal={arXiv preprint arXiv:2312.02949}, year={2023} } -
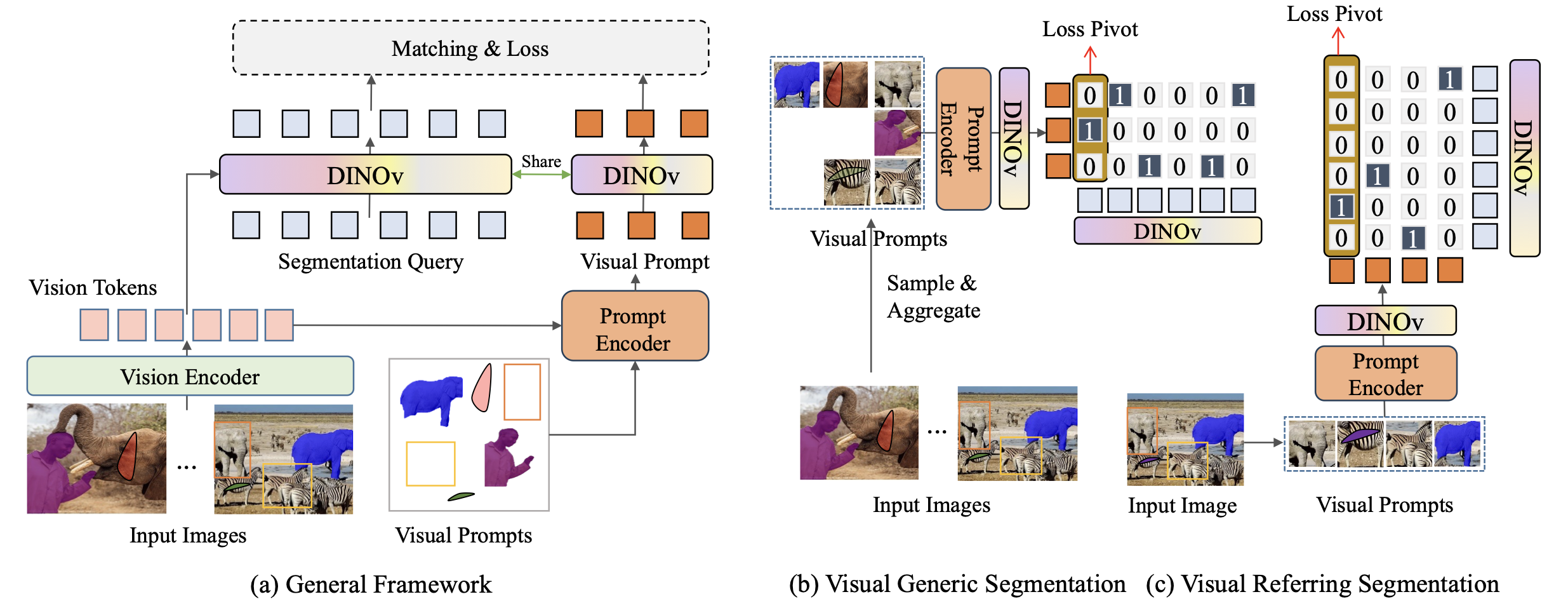 Visual In-Context Prompting.CVPR, 2024
Visual In-Context Prompting.CVPR, 2024@inproceedings{li2024visual, title={Visual in-context prompting}, author={Li, Feng and Jiang, Qing and Zhang, Hao and Ren, Tianhe and Liu, Shilong and Zou, Xueyan and Xu, Huaizhe and Li, Hongyang and Yang, Jianwei and Li, Chunyuan and others}, booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages={12861--12871}, year={2024} } -
 Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks.arXiv, 2024
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks.arXiv, 2024@article{ren2024grounded, title={Grounded sam: Assembling open-world models for diverse visual tasks}, author={Ren, Tianhe and Liu, Shilong and Zeng, Ailing and Lin, Jing and Li, Kunchang and Cao, He and Chen, Jiayu and Huang, Xinyu and Chen, Yukang and Yan, Feng and others}, journal={arXiv preprint arXiv:2401.14159}, year={2024} } -
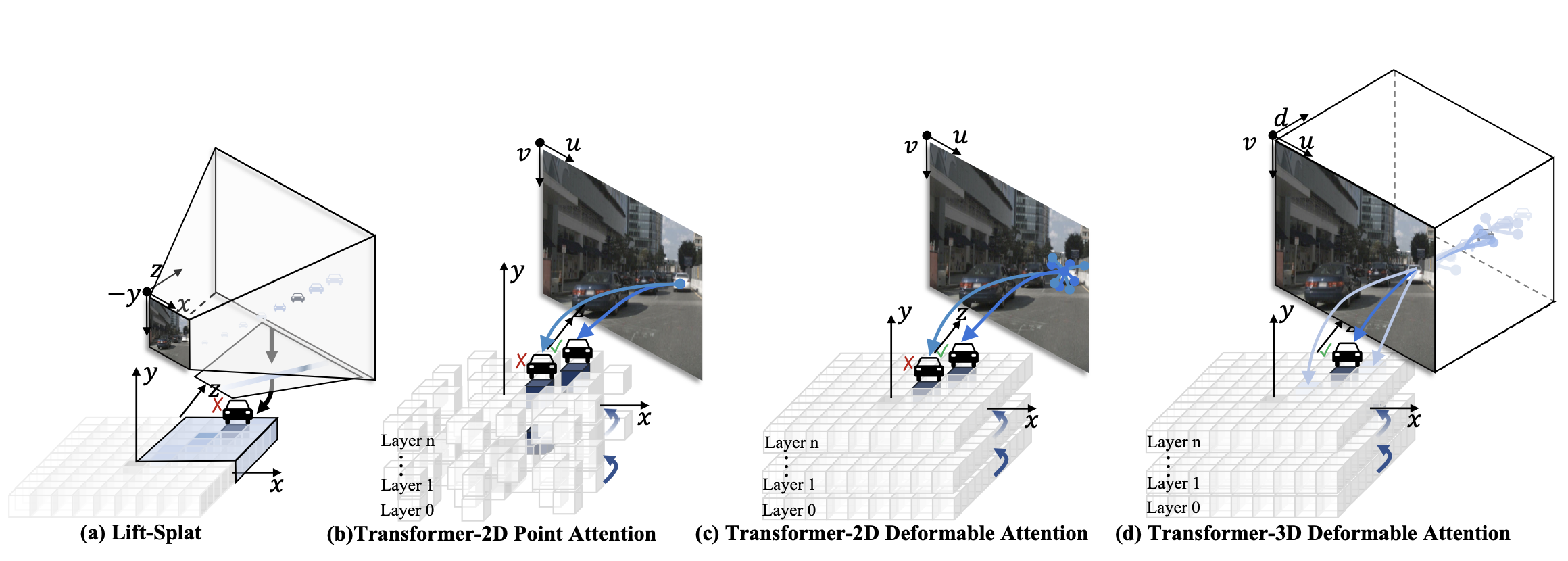 DFA3D: 3D Deformable Attention For 2D-to-3D Feature LiftingICCV, 2023
DFA3D: 3D Deformable Attention For 2D-to-3D Feature LiftingICCV, 2023@inproceedings{li2023dfa3d, title={DFA3D: 3D Deformable Attention For 2D-to-3D Feature Lifting}, author={Li, Hongyang and Zhang, Hao and Zeng, Zhaoyang and Liu, Shilong and Li, Feng and Ren, Tianhe and Zhang, Lei}, booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision}, pages={6684--6693}, year={2023} } -
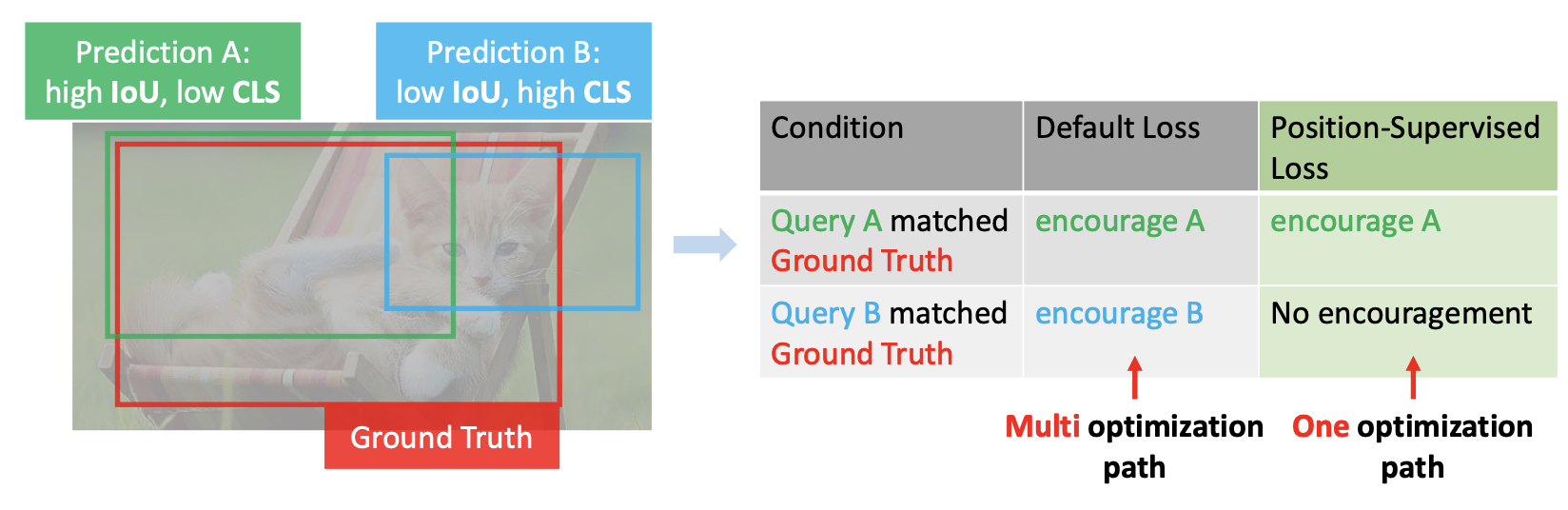 Detection Transformer with Stable MatchingCVPR, 2023
Detection Transformer with Stable MatchingCVPR, 2023@inproceedings{liu2023detection, title={Detection transformer with stable matching}, author={Liu, Shilong and Ren, Tianhe and Chen, Jiayu and Zeng, Zhaoyang and Zhang, Hao and Li, Feng and Li, Hongyang and Huang, Jun and Su, Hang and Zhu, Jun and others}, booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision}, pages={6491--6500}, year={2023} } -
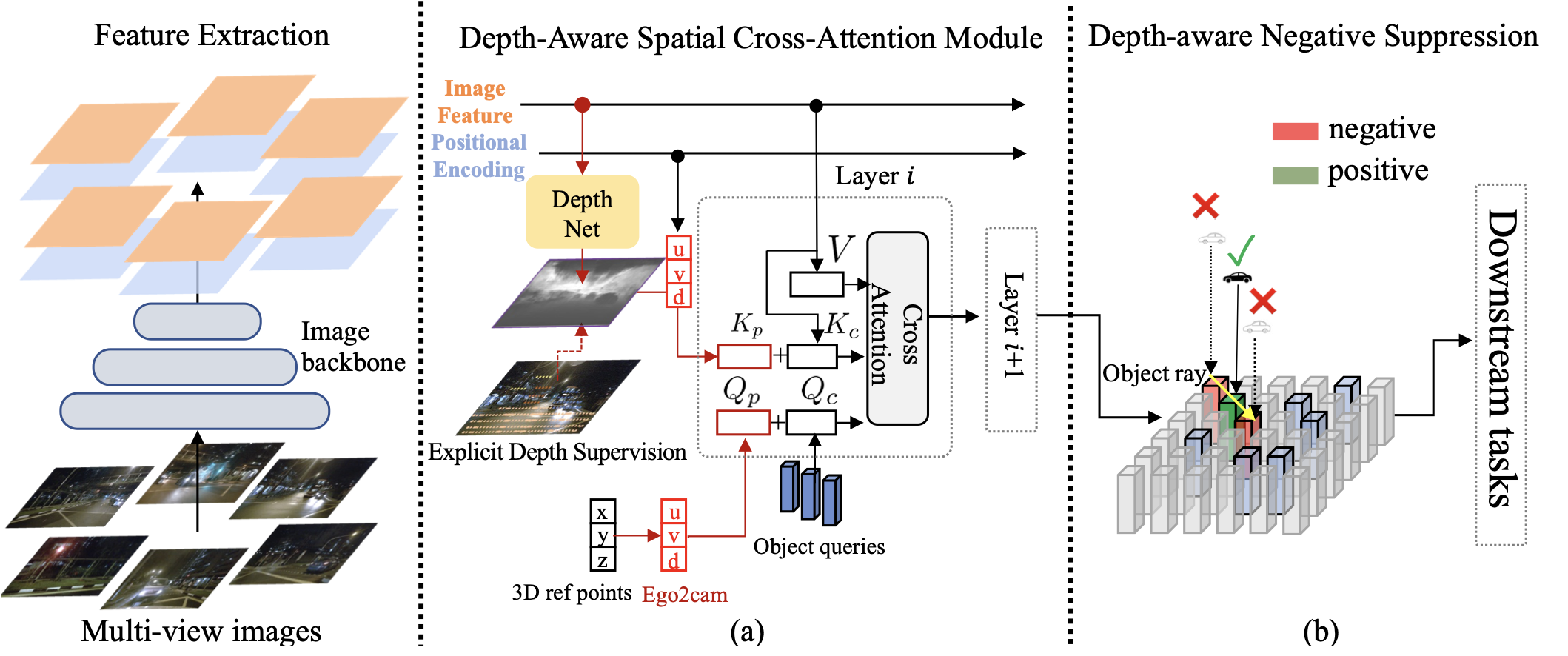 DA-BEV: Depth Aware BEV Transformer for 3D Object Detectionarxiv, 2023
DA-BEV: Depth Aware BEV Transformer for 3D Object Detectionarxiv, 2023@article{zhang2023bev, title={Da-bev: Depth aware bev transformer for 3d object detection}, author={Zhang, Hao and Li, Hongyang and Liao, Xingyu and Li, Feng and Liu, Shilong and Ni, Lionel M and Zhang, Lei}, journal={arXiv e-prints}, pages={arXiv--2302}, year={2023} } -
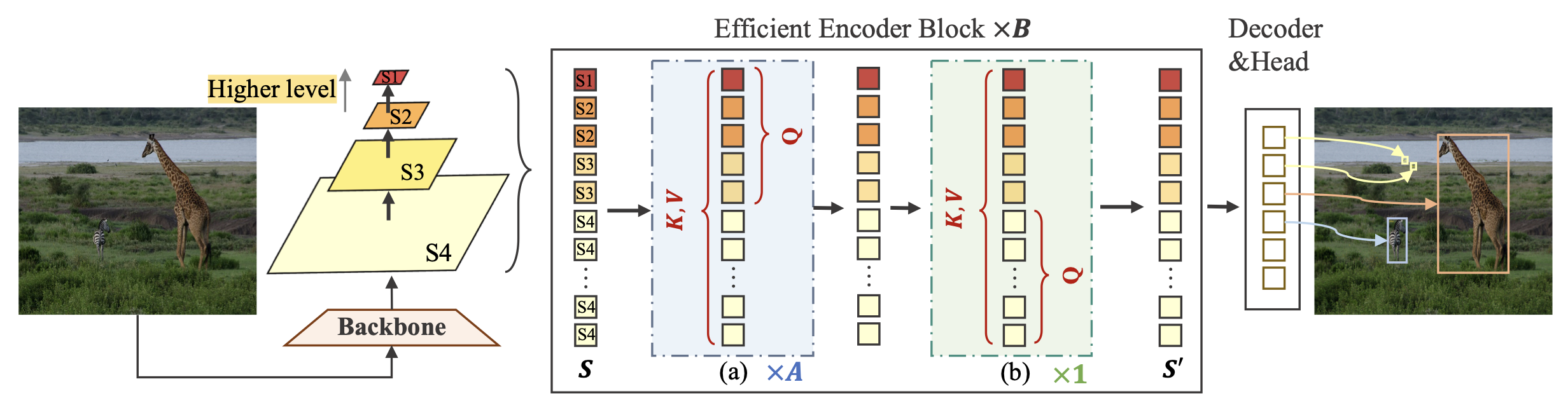 Lite DETR : An Interleaved Multi-Scale Encoder for Efficient DETRCVPR, 2023
Lite DETR : An Interleaved Multi-Scale Encoder for Efficient DETRCVPR, 2023@inproceedings{li2023lite, title={Lite DETR: An interleaved multi-scale encoder for efficient detr}, author={Li, Feng and Zeng, Ailing and Liu, Shilong and Zhang, Hao and Li, Hongyang and Zhang, Lei and Ni, Lionel M}, booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages={18558--18567}, year={2023} } -
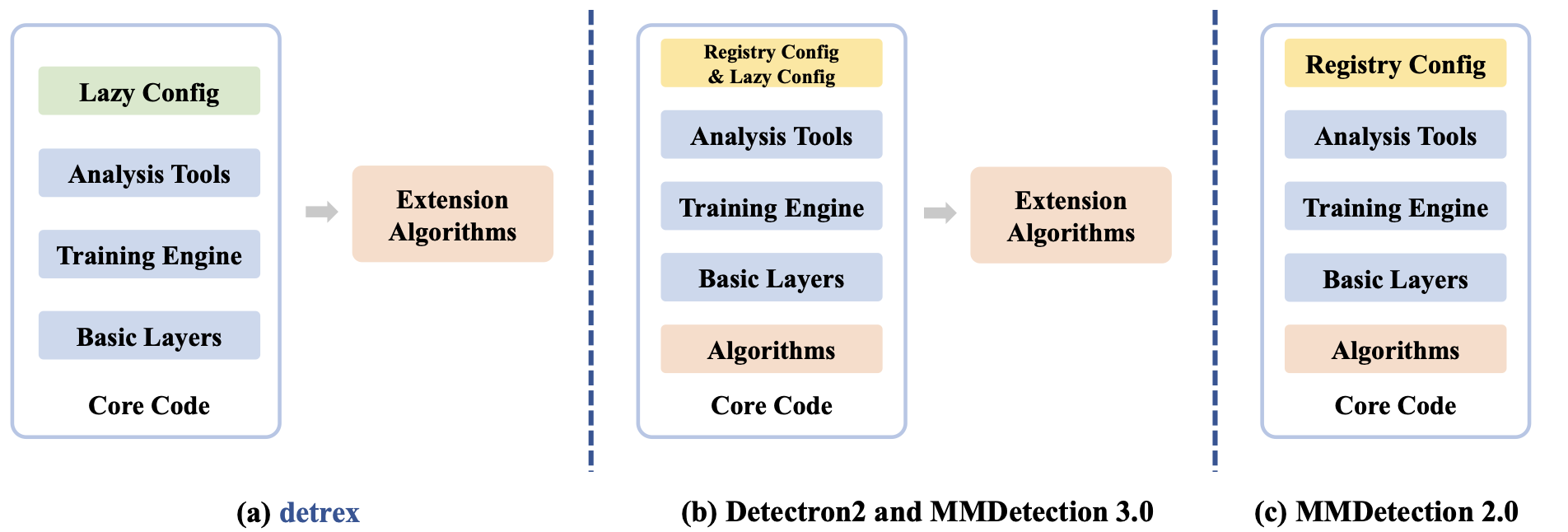 detrex: Benchmarking detection transformersArxiv, 2023
detrex: Benchmarking detection transformersArxiv, 2023@article{ren2023detrex, title={detrex: Benchmarking detection transformers}, author={Ren, Tianhe and Liu, Shilong and Li, Feng and Zhang, Hao and Zeng, Ailing and Yang, Jie and Liao, Xingyu and Jia, Ding and Li, Hongyang and Cao, He and others}, journal={arXiv preprint arXiv:2306.07265}, year={2023} } -
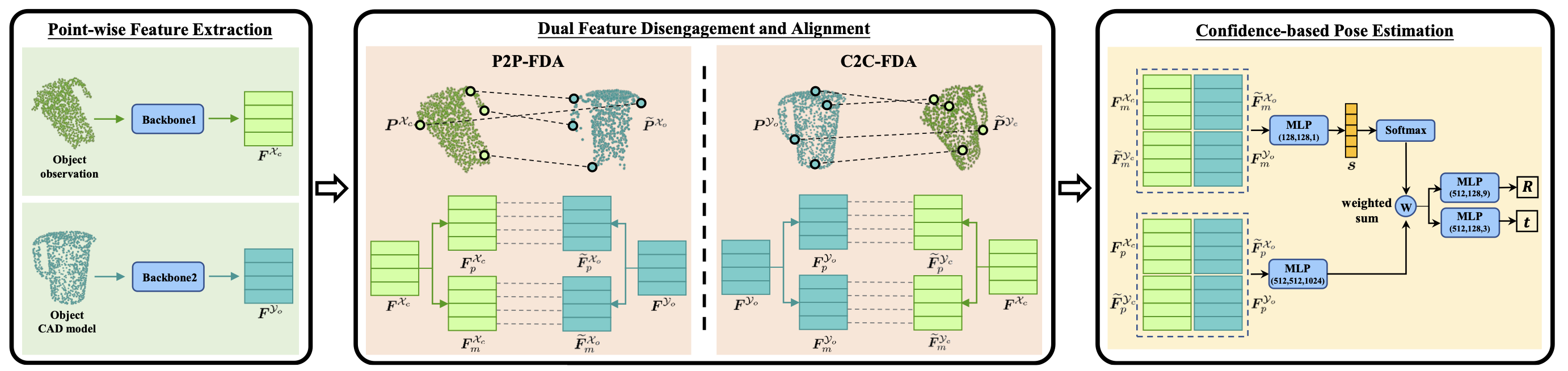 DCL-Net: Deep Correspondence Learning Network for 6D Pose EstimationECCV, 2022
DCL-Net: Deep Correspondence Learning Network for 6D Pose EstimationECCV, 2022@inproceedings{li2022dcl, title={DCL-Net: Deep Correspondence Learning Network for 6D Pose Estimation}, author={Li, Hongyang and Lin, Jiehong and Jia, Kui}, booktitle={European Conference on Computer Vision}, pages={369--385}, year={2022}, organization={Springer} } -
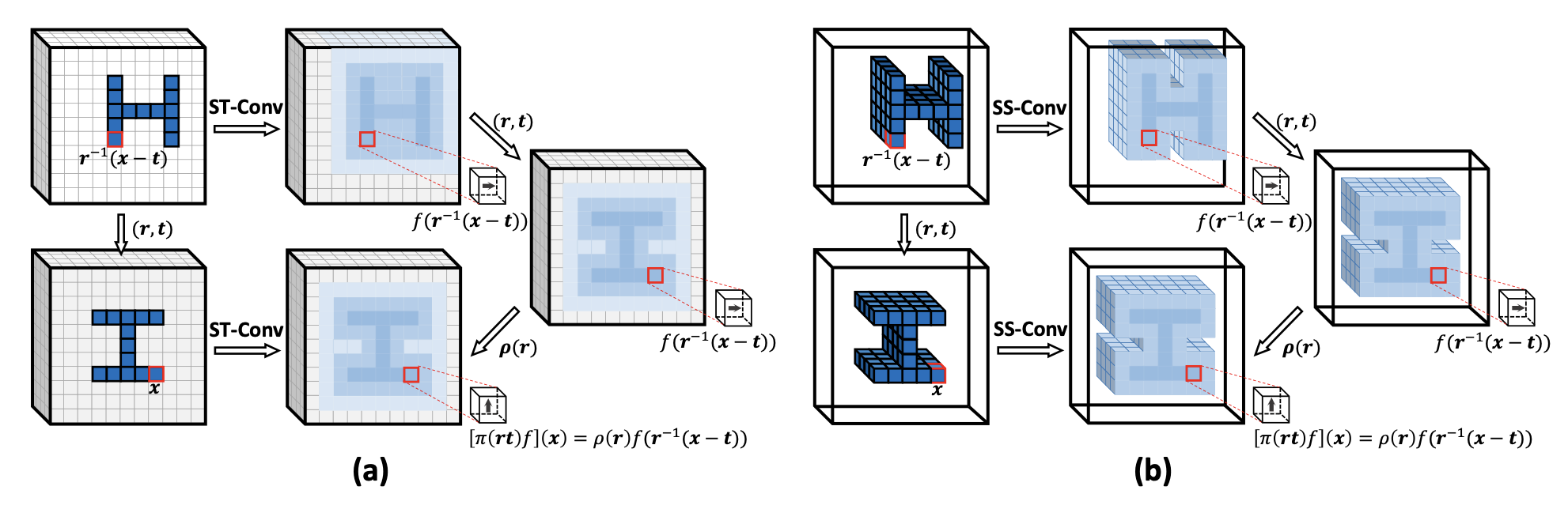 Sparse Steerable Convolutions: An Efficient Learning of SE(3)-Equivariant Features for Estimation and Tracking of Object Poses in 3D SpaceNeurIPS, 2021
Sparse Steerable Convolutions: An Efficient Learning of SE(3)-Equivariant Features for Estimation and Tracking of Object Poses in 3D SpaceNeurIPS, 2021@article{lin2021sparse, title={Sparse steerable convolutions: An efficient learning of se (3)-equivariant features for estimation and tracking of object poses in 3d space}, author={Lin, Jiehong and Li, Hongyang and Chen, Ke and Lu, Jiangbo and Jia, Kui}, journal={Advances in Neural Information Processing Systems}, volume={34}, pages={16779--16790}, year={2021} }
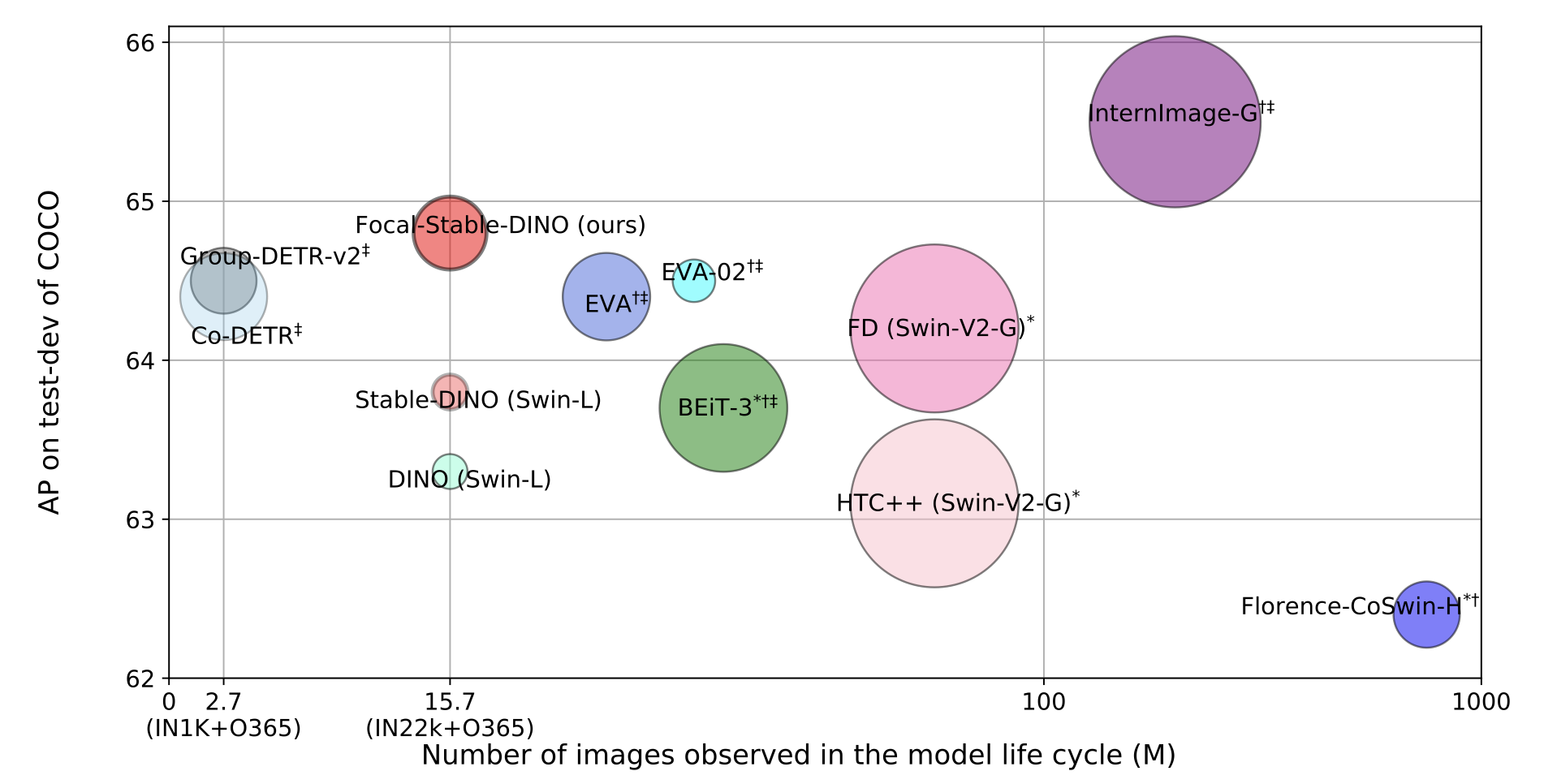
A Strong and Reproducible Object Detector with Only Public Datasets
Arxiv, 2023
@article{ren2023strong,
title={A strong and reproducible object detector with only public datasets},
author={Ren, Tianhe and Yang, Jianwei and Liu, Shilong and Zeng, Ailing and Li, Feng and Zhang, Hao and Li, Hongyang and Zeng, Zhaoyang and Zhang, Lei},
journal={arXiv preprint arXiv:2304.13027},
year={2023}
}